Most QA automation is built around scripts.
A script logs in, clicks a button, checks for expected text, and reports pass or fail. That is useful. It also misses a lot of the reality inside modern software.
MyTidyBiz is a SaaS-based operating system for cleaning companies that supports the full quote-to-cash workflow: quote requests, sales follow-up by SMS or email, customer acceptance, manager review, cleaner scheduling, schedule changes, property details, completed work reports, invoices, tips, and cleaner payments.
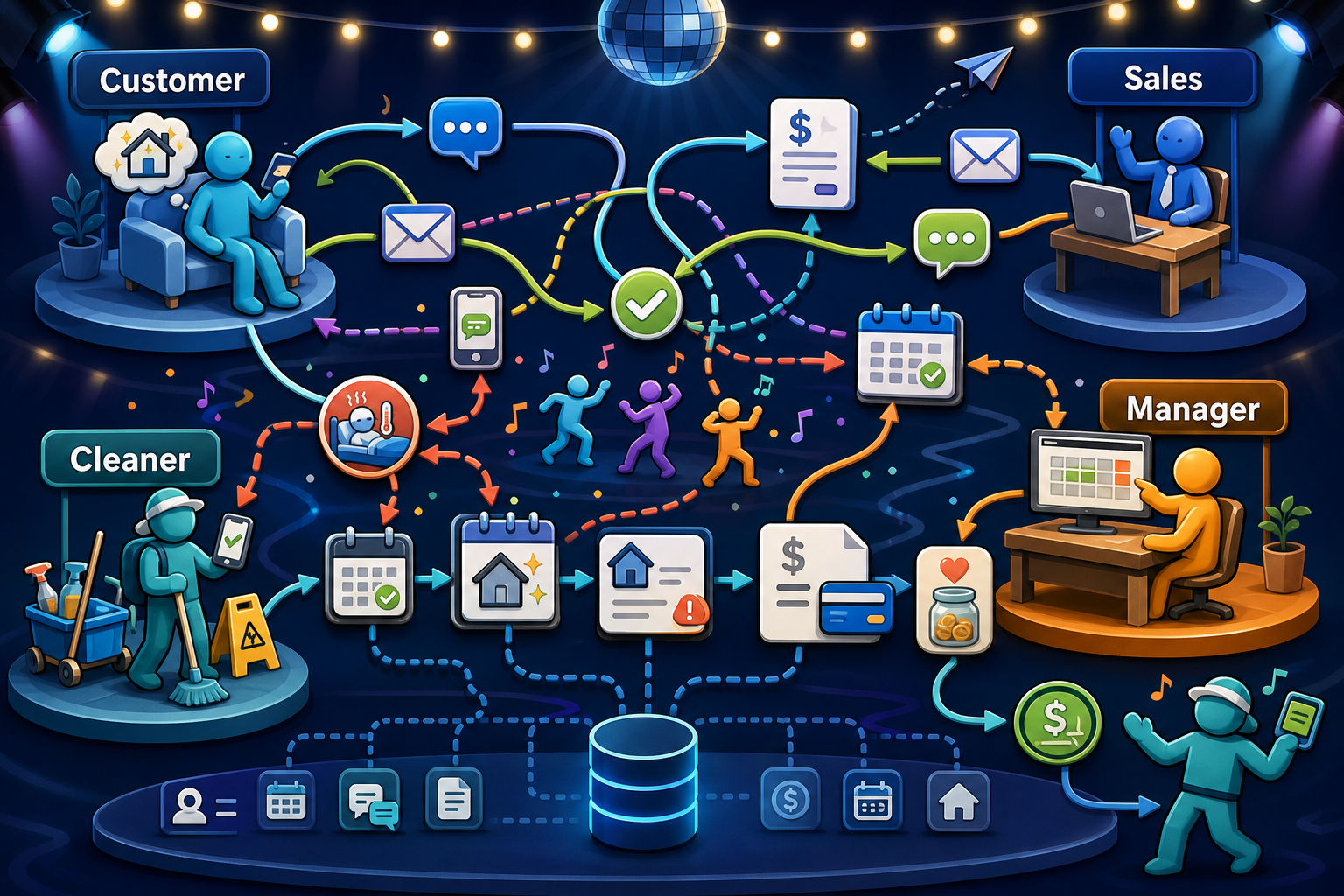
The platform manages a complex dance between customers, sales managers, operations managers, and cleaners communicating through email, SMS, and internal messages. What matters for QA is that every arrow is a handoff: messages, schedules, permissions, job status, customer expectations, payments, and backend records all have to stay consistent. Many of the important defects do not live on one screen. They happen between roles.
So we created OAQA, pronounced "Oak-A": Orchestrated Agentic Quality Assurance. It is our internal role-based autonomous AI QA system: a coordinated QA platform that behaves more like a disciplined test team.
The Problem With Fragmented QA
Take the MyTidyBiz booking process. Broken into pieces, each step looks straightforward:
- a customer requests a quote and describes the property
- a sales manager or the system creates the quote and sends it by SMS or email
- the customer accepts the quote and requests a cleaning date
- an operations manager verifies the booking and schedules cleaners
- the cleaning team cleans the property, updates booking status, and the system creates a report
- the customer receives the invoice, adds a tip, and pays
A traditional automated test can validate each bullet in isolation. The hard part is maintaining context between them: the same customer, quote, property description, accepted booking, assigned cleaners, schedule changes, invoice, tip, and cleaner payout all have to stay connected.
In many QA processes, a human tester is the thing holding that context together. They remember what the customer requested, what sales promised, what the manager scheduled, and what the cleaner actually saw. That works, but it is expensive, slow to repeat, and hard to turn into durable release evidence.
The hardest defects usually sit in those context gaps.
The UI may look correct while the database state is wrong. An invitation may send successfully but create the wrong permissions. A cleaner may see the right page but the wrong booking. A manager action may appear to save while a background process fails quietly.
When that happens, a pass/fail result is not enough. The engineering team needs evidence. What role was acting? What step failed? What changed in the database? What do the logs say? Which boundary is probably broken?
That is the gap we are trying to close.
The OAQA (OakA) Model
We use multiple AI agents operating as defined personas:
- a QA orchestrator
- a sales manager persona
- an operations manager persona
- a customer persona
- a cleaner persona
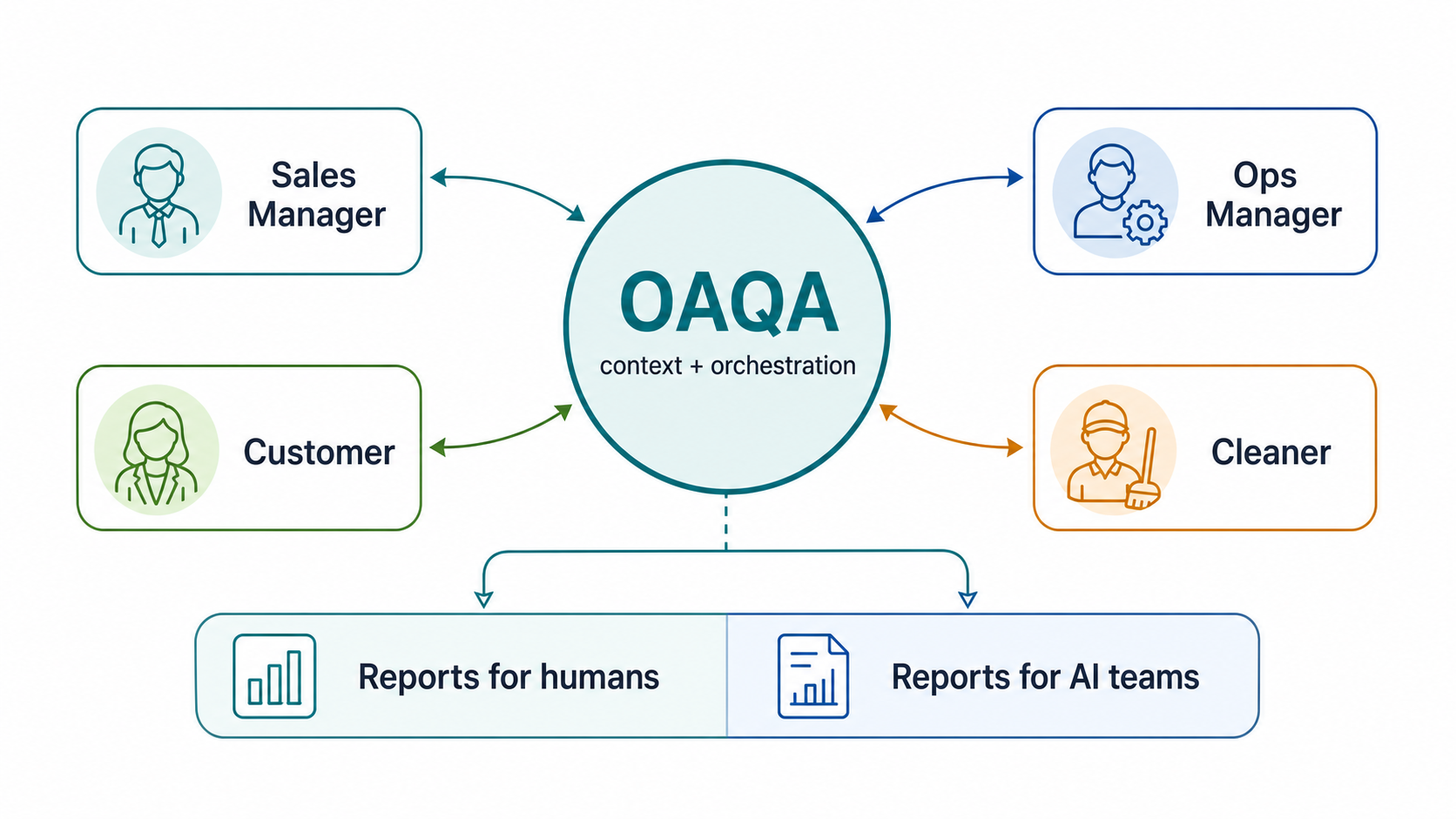
The orchestrator owns the test run. It defines the workflow, validates environment readiness, assigns bounded work to each persona, checks the evidence that comes back, and produces the final report.
The role personas stay in their lanes. Each role uses isolated browser/session context and controlled test identities so actions do not bleed across personas. They know how to do their things and what to expect: if a button does not exist to let them submit a form, they will report that and move on.
The key advantage is context continuity. Each persona only needs to understand its own role, but the orchestrator maintains the larger workflow context across all of them. It knows what the customer requested, what the sales manager quoted, what the operations manager scheduled, what the cleaner accepted, what changed later, and what the system recorded underneath.
The design goal is simple: make the system act less like one giant script and more like a small QA team that knows who is responsible for what.
What A Test Run Looks Like
The process can be managed by communicating with the orchestrator persona through whatever surface has been implemented for the team: a user interface, email, Slack, Microsoft Teams, Telegram, an API call, a DevOps message, or another workflow trigger. The interface matters less than the operating model. The orchestrator receives the request, understands the target workflow or release context, and starts coordinating the run.
OAQA follows this general execution pattern:

- Bootstrap: the orchestrator checks the environment and dependencies
- Role call: the orchestrator checks all personas and their status
- Test suite run: the orchestrator runs the defined workflow, including branches and edge cases, while creating correlated context artifacts for the involved personas
- Test suite wrap-up: the orchestrator creates test result reports
- Wrap-up: the orchestrator creates the final overall report
During the test runs, the orchestrator assigns one bounded action at a time. For example:
- sales manager: create or verify a customer-facing quote step
- operations manager: verify booking details and schedule cleaners
- customer: follow the email-driven path and complete the requested action
- cleaner: accept access, verify permissions, and confirm the correct work is visible
- orchestrator: compare role evidence against logs and database state
The worker agents do not just report "done." They return evidence: screenshots, observed state, URLs, relevant messages, and notes about anything unexpected. The orchestrator uses that evidence to decide the next step or to stop the run and produce a useful failure report.
That distinction matters. The system is not trying to maximize clicks. It is trying to maximize reliable signal.
Output For Humans And AI Teams
The output of an OAQA run is designed for two audiences.

The first audience is the human team. Product managers, QA leads, and developers need a clear report they can trust: what workflow was tested, which personas participated, what passed, what failed, what evidence was collected, and where the likely failure boundary is. That report supports release decisions, triage, and stakeholder communication.
The second audience is the AI-assisted development team. If AI tools are going to help fix the problem, they need more than a failing test name. They need the complete workflow context and observations from the run:
- the customer, booking, property, schedule, invoice, and payment context
- the persona that performed each step
- expected behavior versus observed behavior
- screenshots, URLs, messages, and UI state
- relevant log entries and database observations
- the orchestrator's diagnosis of the likely failure boundary
That makes the OAQA report useful as both a human QA artifact and an AI development handoff. A person can review it, challenge it, and prioritize it. An AI development agent can consume it as context for debugging, code review, or repair work. This added context saves time and tokens.
How This Benefits The SDLC
This changes QA from a late-stage bottleneck into a repeatable delivery capability.
For product and engineering teams, the benefits show up in a few practical ways.
Better cross-role coverage. The system exercises workflows the way real users experience them: across roles, emails, permissions, and state transitions.
Lower manual QA load. Repetitive smoke and regression checks can run without requiring a person to manually replay the same workflow every release.
Clearer defect evidence. Failures come with context: role, step, expected state, observed state, screenshots, logs, and database clues where available.
Faster diagnosis. Engineers get a narrower failure boundary instead of a vague "the test failed" message.
Reusable regression capability. Once a workflow is modeled, it can become part of a release smoke pack or scheduled regression run.
The point is not to remove human judgment from QA. The point is to stop spending human judgment on repetitive replay when it can be spent on risk, edge cases, product quality, and release decisions.
Self-Evolving QA Workflows
Another advantage is that OAQA can support self-evolving QA workflows.
After each pull request, the orchestrator can use user story acceptance criteria, PR comments, commit notes, and code changes as inputs. A specialized product owner persona reviews those inputs from the feature perspective. That persona is aware of the product goals and objectives, so it can reason about what changed, which roles are affected, what customer or business outcome matters, what workflow context is at risk, and what evidence should be collected.
The orchestrator can then use the product owner persona's findings to propose test scenarios and workflow updates: new checks for new features, revised steps for changed behavior, retired checks for removed functionality, and targeted regression runs for the personas most likely to be affected.
That keeps the QA model connected to the product as it evolves. Instead of a regression suite slowly drifting away from the real application, the test workflows can be updated alongside the code changes that created the need for them. The OAQA workflow pack can also be versioned with the software release, so teams know which personas, checks, and evidence requirements belong to each product version. For sensitive areas, those updates can still go through human review before becoming part of the durable QA pack.
Implementation Details That Matter
The useful part of this model is not just the prompts. It is the operating structure around the agents.
We keep a shared QA workspace separate from the application repo. That keeps test plans, role instructions, evidence requirements, and run reports organized without turning the product codebase into an experimental scratchpad.
Each persona gets isolated runtime context. Separate browser profiles and controlled identities make it possible to test realistic cross-role behavior without contaminating sessions.
The orchestrator publishes role context before execution. Each worker knows its identity, its permitted surface area, and the exact workflow it is responsible for. The system is intentionally role-bound.
We also separate reasoning from execution. The orchestrator uses the stronger reasoning model because it is responsible for sequencing, validation, and diagnosis. The worker agents can use lower-cost models because their work is bounded and repetitive. That keeps the cost profile practical.
Finally, the system is evidence-driven. A role agent is not allowed to claim success without returning observable proof. The orchestrator is responsible for validating that proof against the larger run.
What We Still Keep Guarded
Agent-based QA is powerful, but it needs boundaries.

One reasonable concern is that the orchestrator knows a lot. That is intentional, but it does not mean the orchestrator should have unlimited authority. OAQA is designed around a simple principle: broad context, narrow authority.
The orchestrator can coordinate personas, compare evidence, read approved logs or state, and produce reports. It should not mutate infrastructure, override business rules, access production data casually, or act outside the boundaries defined for the run. The orchestrator is only an observer and reporter, not an operator.
We do not want agents mutating infrastructure. We do not want them improvising outside their assigned role. We do not want them handling production data casually. We do not want a confident narrative in place of evidence.
So the system is designed with guardrails:
- explicit role boundaries
- controlled test identities
- isolated browser sessions
- read-only access to environment evidence where possible
- human review for sensitive workflows
- durable reporting after each run
The best use of autonomous QA agents is not unchecked autonomy. It is disciplined autonomy inside a well-designed process.
Why This Is Commercially Interesting
AI development tools generate more code, faster. The bottleneck is shifting. Teams can now produce features, fixes, and refactors at a pace that traditional QA processes were not designed to absorb. There is simply more code moving through the system, and every extra change creates more places where workflow context can break.
That is why the output layer matters commercially. OAQA does not just say that a test failed. It creates the evidence package needed for both human review and AI-assisted repair, which makes QA a faster feedback loop instead of a slower gate at the end of development.
This model is a strong fit for platforms with:
- multiple user roles
- multi-step workflows that require approvals, audits, or review gates
- multi-surface workflows such as email, SMS, invitation links, or external notifications
- fast-moving products where QA workflows need to stay current with frequent pull requests
- AI-assisted development teams that need high-context QA reports, not just failing test names
If your team is dealing with regression bottlenecks, multi-role workflow complexity, or too much time lost reproducing defects, this is exactly the kind of problem this model is designed to solve.
Reach out if your team needs assistance. We can help you stand up your own OAQA system, or we can host a virtual QA team that you can interact with through Slack, Microsoft Teams, or your preferred workflow surface.
Want to test your workflows this way?
CloudZoom can help map your critical product workflows, design role-based QA personas, and build a practical OAQA system around your real environment.
TALK THROUGH YOUR QA WORKFLOWS